

分类问题(Classification)
推测值X |
X>=0.5 | X<0.5 |
|---|---|---|
输出值 Y |
1 | 0 |
这样的方法在某些情况下并不好用,因为有时候一个异常值会大大影响最后计算出的值
为了解决这样的问题,我们将公式变换一下:
这样的话,生成的值就会落在0~1之间,如图:
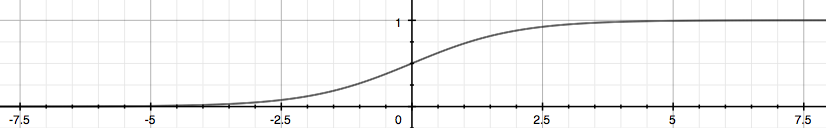
当然在概论论中:
那么问题来了,我们要这个
hθ(x)有什么用呢?这就引出了
决策边界(Decision Boundary)这个概念了
首先对上式进行分析
Remember
所以在数学计算中,我们可以这么表达:
决策边界(Decision Boundary)就是将y=1和y=0分开的那条线
Example:
该例子中,X1 = 5就是决策边界
X1 <= 5 X1>5 Y = 1 Y = 0 当然,决策边界也可以是曲线
e.g.
逻辑回归模型(Logistic Regression Model)
Cost Function
在逻辑回归中,我们不能用和线性回归相同的那个Cost Function了,如果使用相同的,会造成输出值呈波浪状,无法收敛
逻辑回归模型的Cost Function:
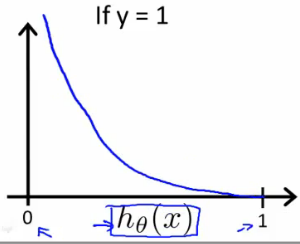
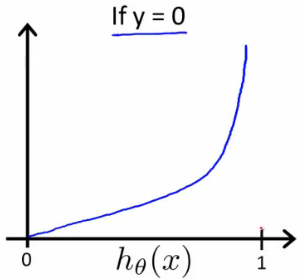
而在下式中,我们更是将这两个式子融为一体:
相应的Cost Function为:
将其向量化之后得到:
梯度下降(Gradient Descent)
一般来说,梯度下降的方法为:
计算之后,上式可化为:
它的向量化表达式为:
更先进的算法(Advanced Optimization)
- Conjugate gradient
- BFGS
- L-BFGS
首先我们需要写一个函数来计算出与θ相关的两个量
为此我们可以先写出一个返回值为它们两个的函数
1 | function [jVal, gradient] = costFunction(theta) |
之后我们可以使用Matlab自带的fminunc()函数计算相关值
1 | options = optimset('GradObj', 'on', 'MaxIter', 100); |
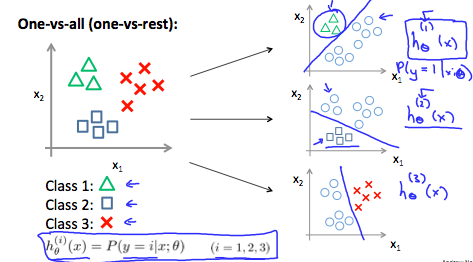
多类别分类(Multiclass Classification: One-vs-all)
当我们需要处理的分类问题拥有超过两种类别时,我们用y = {0,1,…,n}代替y = {0,1}
其原理为:
我们在每个分类y = i中,我们将所有样本分为Xi和非Xi,并将其拓展到每个分类之中
过度拟合(Overfitting)
在取得预测曲线时,由于我们选取的特征变量不同,可能导致三种情况
| 欠拟合 | 正常 | 过拟合 |
|---|---|---|
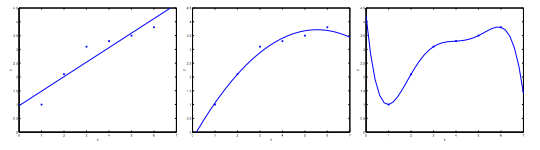
在上图中,欠拟合可能为y = θ0+θ1X
正常可能为y = θ0+θ1X+θ2X²
过拟合可能为y = θ0+θ1X+θ2X²+θ3X³
为解决上述问题,我们通常采用以下两种方法:
| 减少特征 | 正则化 |
|---|---|
| 人为选择应该留下的特征 | 留下所有特征,但减小其权重 |
| 利用模型选择算法 | 正则化在特征多且影响小时效果好 |
Cost Function
如果我们发现输出图像已经是过拟合了,那么我们就可以以增加它们的代价(
cost)来降低它们的权重
例如:
为了减少θ3x³和θ4x⁴的影响,我们调整Cost Function为:
这样在迭代时,
θ3和θ4会逐渐趋于0,θ3x³和θ4x⁴的影响也会减小到一定程度
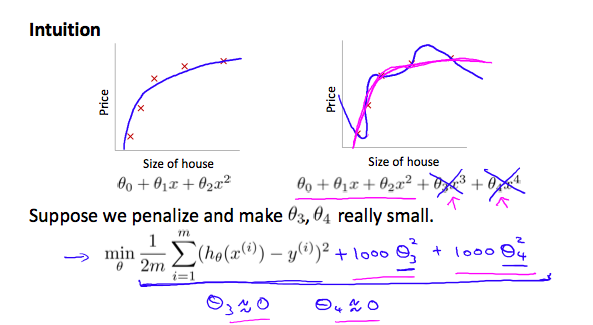
当我们拥有很多特征时,便可以将正则化θ这个任务简化为一个方程:
其中
λ被称作正则化参数(Regularization Parameter)
- 当然,当
λ取过大时,可能造成欠拟合
线性回归正则化(Regularized Linear Regression)
线性回归和逻辑回归,都是可以进行正则化操作的
首先我们来讲线性回归,对它来说,分为梯度下降法和正规方程法
首先,梯度下降,我们先把
θ0从中分离开来其中
λ/m*θj代表这我们的正则化操作,同时将上者合二为一得:
然后再用正规方程来表示线性回归
在正规方程中,我们只要加一个项就可以完成正则化了
L是一个左上是0其余元素均为1的(n+1)*(n+1)矩阵
逻辑回归正则化(Regularized Logistic Regression)
通过正则化逻辑回归,我们可以有效地避免过拟合的出现,如下图,粉色的分类方法就更加科学:
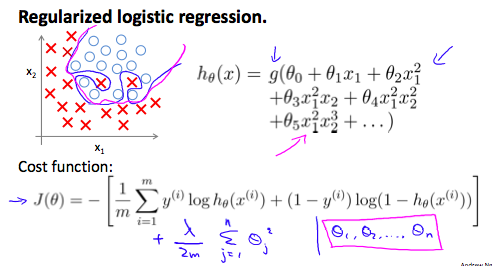
Cost Function
会看一下我们之前的逻辑回归的代价函数:
我们对此做出的调整就是在它最后加上了一项:
在新加入的式子中,
意味着明确地排除偏项(explicitly exclude the bias term)θ0
举个例子:如果我们有一个0到n的向量θ,该算式计算时就跳过了第0项,直接计算1到n项
因此,在计算时我们要持续地上传两个值:


