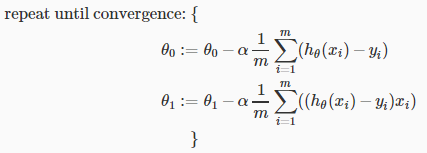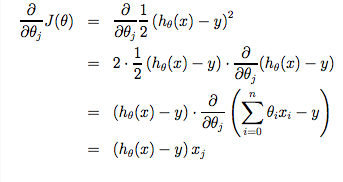Welcome
什么是机器学习
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E
大体为:机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。
监督学习(Supervised Learning)
给定我们所认为正确的输入输出,让机器向此方向学习
监督学习分为两大类:
Regression&Classification即
回归问题和分类问题
回归问题(Regression)
根据之前的数据预测出一个准确的输出值
例子:给定一个人的照片,我们需要按照片预测他的年龄
分类问题(Classification)
0/1离散型输出
例子:给定一个得肿瘤的病人们的样本,预测肿瘤是良性或者恶性
非监督学习(Unsupervised Learning)
在我们不知道输入的数据的作用时,帮我们把数据处理成它应该成为的样子
非监督学习不存在预测结果方面的反馈
聚类(Clustering)
例子:给定一组多达1000000份的基因组,想办法自动地将其分类为与何有关基因,如与寿命有关的基因、与地域有关的基因
非聚类(Non-clustering)
例子:将嘈杂的聚会中的音乐声和人声分离出来
模型与代价函数
Model Representation
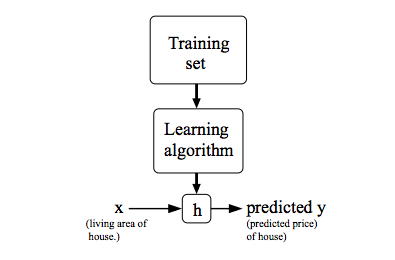
在监督学习中,我们的目标是,给定一个训练集,执行假设函数
h(x):X->Y以获得一个合适的预测值y,h(x)是一个关于x的函数,与之后的代价函数不同,代价函数J(θ)是关于θ的函数该
假设函数h(x)在该节中以线性函数出现,一般形式为:
当我们想要预测的值为连续的,如上预测房价,则该问题为回归问题
当我们想要预测的值为小型离散值,则该问题为分类问题
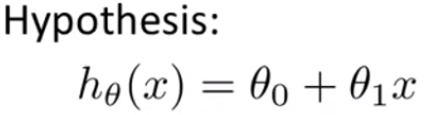
Cost Function
代价函数又称
平方误差函数,在下式中,m代表训练集基数
将它分块来讲的话,就是算每次预测值与实际值的误差的平方均数
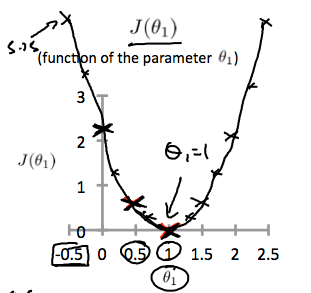
以下是J(θ)应该的大概轮廓图 :
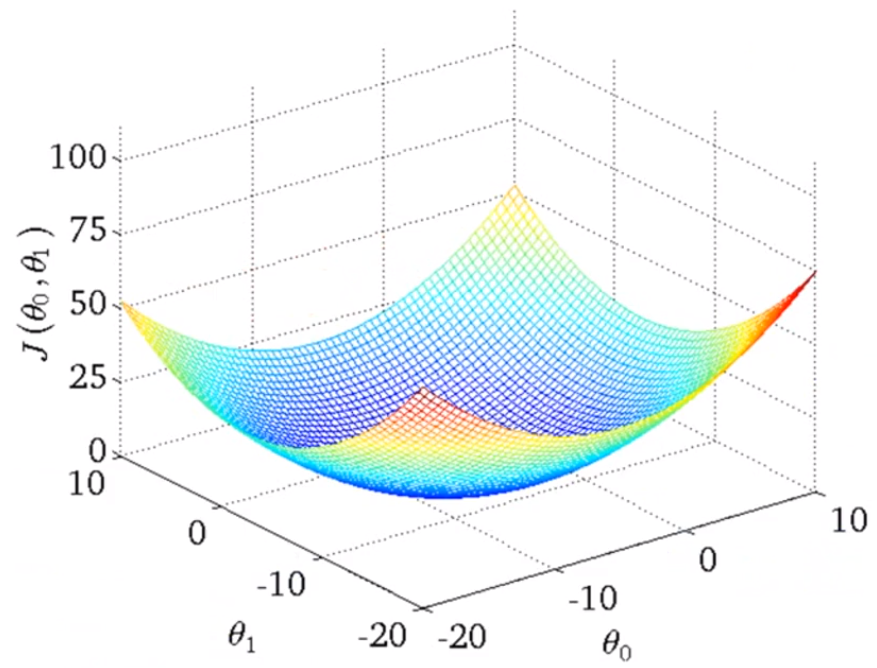
更精确的图会像这样:
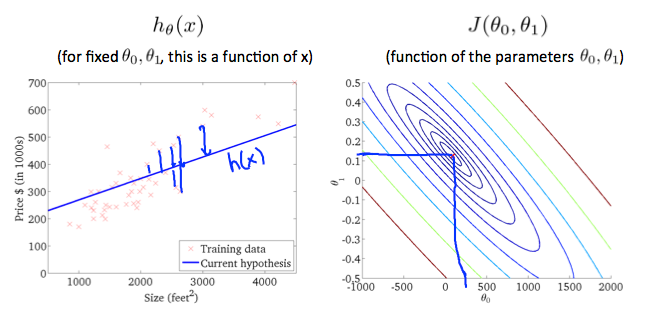
在二维中,我们可以用截面图来表示这样的三维图形:
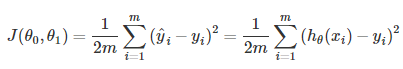
参数学习(Parameter Learning)
梯度下降(Gradient Descent)
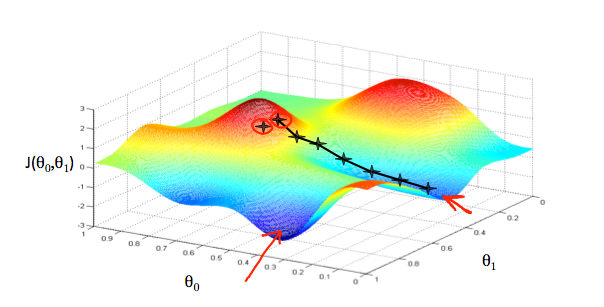
梯度下降法即每次都寻找能降低代价函数J(θ0,θ1)的最优方向改变θ0、θ1,直到找到无法进一步下降的局部最优点:
在梯度下降中,通用公式为:
在上式中,j~{0,1},参数
α为学习速率,它控制我们以多大幅度更新这个参数θj当
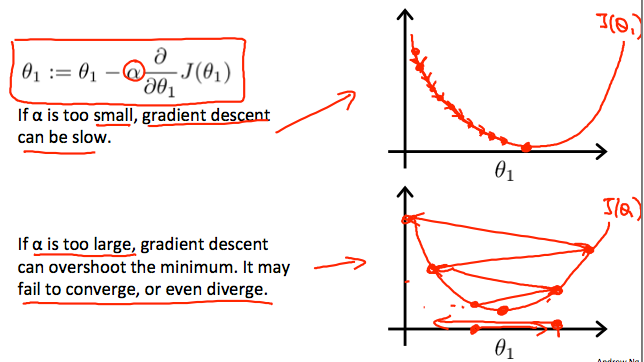
α过大或者过小时,算法的效果都不会很好
- 过小则梯度下降速度太慢
- 过大则有可能无法收敛,甚至越来越偏离收敛点
在书写代码时,注意要同步更新θ0、θ1:
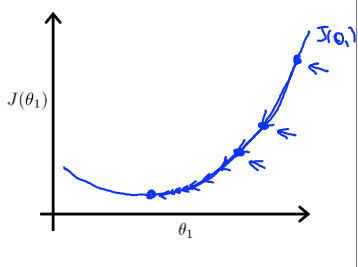
要注意,梯度下降正常的输出为这样,每次θ向着收敛点变化,θ变化得越小:
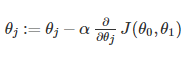

梯度下降与线性回归(Gradient Descent For Linear Regression)
在上述例子中,我们得到了梯度下降和代价函数的函数表达式,接下来将两者结合起来:
其中关于梯度下降中的具体计算为:
像这种每次更新值都着眼于全部训练数据的梯度下降算法我们称之为批量梯度下降(Batch Gradient Descent)